
K. Onda
December 6, 2020
ICONIX - 1.Domain分析
ICONIXの分析工程
ここでは、ICONIXの分析工程を見てゆきます。最初に全てのベースとなる静的モデルのドメイン分析、続けて動的モデルのユースケース分析、ロバストネス分析、そしてシーケンス分析と進みます。この過程で、全ての主要な用語はドメイン分析で作成したドメインモデル(用語集)を元に行わなければなりません。
例えば、ドメインモデルに「ユーザー」と定義したならば、以降の分析に現れる用語は「利用者」ではなく「ユーザー」です。用語のブレを許さずに「ユーザー」に統一しなければなりません。逆に「利用者」の方が適切だと思ったならば、以降の分析で使う文書の訂正より先にドメインモデルを書き直す必要があります。それほどドメインモデルは影響力の高いものなわけです。
では、そのドメインの分析から始めたいと思います。
ドメイン分析
ドメインモデルは全ての工程の基本となります。何故ならそれが正規の用語集となるからです。フワフワとした曖昧な言葉を棄て、正確で本質的な用語を捉えてゆくと、思考がクリアになります。また、ドメイン用語は属性も定義しますので、誰かが「ユーザー」と記述 (会話) した際、そこに「ユーザーID」「氏名」「住所」等の関連属性が含まれているか否かという点も明確になります。
ですから、仮に「ユーザーID」や「氏名」「住所」等が含まれていた場合は、記述や会話の中で「ユーザー」という表現が出た場合にこれらの情報も含むことが分かるわけです。厳密さだけではなく簡潔さも手に入れる事ができます。会話と文書が徐々に変わってゆくのが体験できるかも知れません。
Before: システムはユーザID, 氏名, 住所を画面に表示する。
After : システムはユーザー情報をユーザー詳細画面に表示する。
ドメインモデルの抽出
ドメイン分析を行うには、最初にドメインモデルの候補を抽出します。これはドメインエキスパートが提供するユーザーストーリー等から導き出します。何やら難しそうに聞こえますが、ドメインエキスパートというのは業務に詳しい担当者、ユーザーストーリーとは業務の流れを説明した文章です。要は「業務担当者のお話を聞いたり文章を読んだりしてキーワードを見つける」という作業に過ぎません。
ユーザーストーリーが存在しない時は、関連がありそうな文書を漁ってみます。それは簡単なシステム化の企画書かも知れませんし、何らかのマニュアルや、時には誰かが残したメモかも知れません。文書化されたものがなければ業務担当者へのインタビューで代替するのも一案です。
主要なドメインモデルの選出
ドメインモデルの候補が抜き出せたら、候補の中から主要なドメインモデルを選出します。対象システムとの関連性が薄そうなモデルを一旦脇に寄せて主要なモデルだけを選りすぐります。
例えば営業支援システムを開発しているとします。“営業担当”, “売上実績” 等は関連が深そうですが、“社用車”, “出社時刻” 等は関連が薄そうです。こうして関連の深そうなモデルを主要なドメインモデルとします。
これが重要なのは、直前の工程で多くの候補が出た場合 その全てを分析するのは大変だからです。逆に利用頻度が高く重要なものに絞って分析すれば時間の節約になり効率の良い仕事ができます。
その他のモデルの分析も無意味ではありませんが、分析初期の貴重な時間が惜しいですし 分析初期の精度にもあまり期待できません。それよりかは重要なドメインモデルに絞って分析し、フィードバックを得ることで徐々に分析精度を高めた後に、その他のモデルを追加した方が効率的という考え方です。
スコープ外に区分けしたドメインモデルも、後から必要だと分かった時に分析することは可能なので、ここでは一旦スコープを限定してしまいます。
モデル名のチェック
抽出したドメインモデルには最初から名前が存在しますが、あくまで仮の名称として捉えてください。分析が進んでも名前が変更されない保証は何一つありません。「今までそう呼ばれてきたから」「その時はその名前が良さそうに見えたから」という程度の理由で名前付けされている可能性も高く本質的な名前とは限りません。勿論それが最適な名前である可能性もありますが、最初はそれを疑ってください。
例えば、以下に示すのはあまり良くない名前の例とその改善例です。
| # | 問題点 | 例 | 改善方針 | 改善例 |
|---|---|---|---|---|
| 1 | 抽象的すぎて他のモデルと衝突しがち | 担当者 | 修飾子を付けて具体化 | ○○社経理担当 |
| 2 | 名詞に見えるが実体は動詞 | 承認 | 別のモデルの「操作」に分類 | 「経理部長」内の「承認()」に移動 |
| 3 | 同じものに複数の名称が存在 | - クレジットカード - カード |
モデルを統合 | クレジットカード (カードは削除) |
| 4 | 同列の名前の切り口が異なる | - セールスマン - 女性社員 |
切り口を統合 | - 男性営業職員 - 女性営業職員 |
関連の洗い出し
一通りドメイン用語が洗い出せたなら、次に用語同士の関連を洗い出します。最初に単純な線で関連を引いてみましょう。ここで注意するのは、厳密に定義しすぎると多くの用語同士に線が引かれてゴチャついてくる事態です。原則としてドメイン分析はモデリング作業なので、全て正確に洗い出すというより「大事な部分を強調し細かい部分は無視する」というスタンスが重要です。余計な部分を削ぎ落としてこそ大事な部分が目立つからです。
関連の分類 (Option)
用語間に線を引き終えたら、次に線を三種類に分類しましょう。「関連」「汎化」「集約」の関係に大きく分類できれば良いと思います。
| # | 項目 | 説明 |
|---|---|---|
| 1 | 関連 | 用語同士の一般的な関係です。“has a"とも表現され、一定期間相手の参照を持ちそれを使用します。 AはBを使う、AはBを生成する…等です。 |
| 2 | 汎化 | 用語同士の継承関係です。“is a” とも表現され「課金ユーザー」は「ユーザ」の性質を継承する…等です |
| 3 | 集約 | 用語同士の保有関係です。“owns a” とも表現され「バイク」は「エンジン」を保有する…等です |
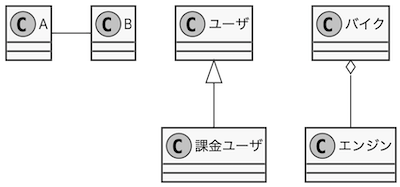
関連の分類は慣れるまでは省略しても構いません。関連の有無さえ確認できれば(単純な線さえ引いてあれば) 大まかな分析は可能ですし、ある程度なら関連の分類は推測できるからです。また、次節の「分類の詳細化」も同じ理由で一旦省略しても構いません。
分類の詳細化 (Option)
一旦大きく分類が出来たら、次に関連を詳細化しましょう。
| # | 項目 | 説明 |
|---|---|---|
| 1 | 関連 | 用語同士の関連に名前をつけ、関連が片方向のものであれば関連線を矢印(<—)に変更します |
| 2 | 汎化 | 汎化関係を「汎化」(<I—)と「実現」(<I…)に細かく分類します |
| 3 | 集約 | 集約関係を「集約」(◇—)と「コンポジション」(◆—)に細かく分類します |
最初に関連先の方向を詳細化します。例えば、AがBを暫く利用しているだけの関係で、BがAを利用することがなければ関連線に方向 (誘導可能性) を持たせます。関連線が矢印になっていない場合は暗黙的に双方向の関連を意味します(またはラフに関連を引いただけかも知れません)。矢印で線が破線の場合は、ごく一時的な利用関係を意味し依存と呼びます。関連としては特に弱いものです。
続けて、汎化の中から実現を抽出します。責務を表現する抽象的なインターフェイスとそれを履行しているクラスの関係を実現と言い、汎化で利用した白抜き矢印の線を破線にすることで表現します。下の例で説明すると、ユーザの情報を守るためにユーザには情報を暗号化する責務をもたせてあり、この責務を「情報保護」インターフェイスで表現しています。
最後に、集約の中からコンポジションを抽出します。具体例としてバイクとエンジンの関係に注目します。この関係ですが、バイクがエンジンを保有(owns a)しているというより、もはやエンジンはバイクの一部という関係です。その証拠に、バイクを破棄する時には大抵エンジンも一緒に破棄します(ライフサイクルの一致)。この(is a part of)の関係が成立する時はより強力な包含関係(コンポジション)が適用されるのです。
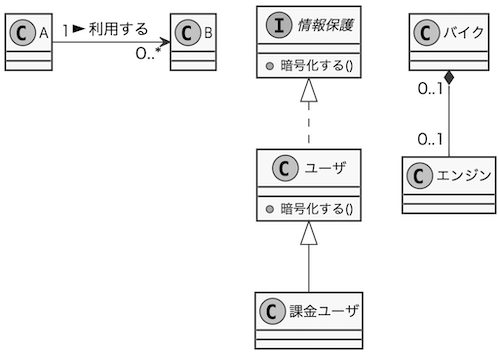
多重度の定義
関連の詳細化が終わったら、汎化(実現) 以外の関連に数的な関係(多重度)を定義します。例えば「バイク」と「エンジン」の多重度は 1:1 です。最大300人が入れる映画館とお客さんの多重度は 1:0..300です。Webページと閲覧者の関係は、0..*:0..*です。どちらも0にも出来ますし、無限にもできるからです。
但し、バイクの生産中の過程も管理する様であれば、組立て前のバイクや、部品としてのエンジンもあるかも知れません。バイクから見てエンジンは0か1、エンジンから見たバイクも0か1、そうなると双方の関係は 0..1:0..1となりそうです。
(0…1は 0以上1以下を表します)
ドメインモデル (暫定版)
以上で、暫定版のドメインモデルは完成です。最初は慣れないと思いますが、慣れてしまえば表現力の高い強力な図です。
ここまで詳細化できるのであれば、プログラムにまで落とし込めそうな気がしますが、そこまで考慮すると細かな変数や操作が増えてノイズとなってしまいますので、一旦シンプルな概念図にとどめておくのが適切です。(あと一歩で本物のクラス図という状況なのでこの時点でプログラム化は比較的簡単です)
ドメイン用語集に属性や操作の情報が殆ど載っていないことが気になるかも知れませんが、ロバストネス分析やユースケース分析の際に本格的に洗い出されるため、現時点ではそれほど心配する必要はありません。最初の分析はしばし考えすぎて過剰分析になる傾向があるため、数時間程度で切り上げるのが通例です。
まとめ
今回は、分析工程の最初として、ユーザーストーリーからドメインモデルを洗い出しました。その後、モデル間の関連を確認し、可能であればそれらに詳細な情報を与えました。これは最初の分析としては充分ですし、ユースケース分析を確認しないままこれ以上の分析しても、過剰な詳細化に陥る恐れも高く危険だと判断し、次の分析に進むことにしました。
«今回実施したこと»
| # | 項目 | 説明 |
|---|---|---|
| 1 | 目的 | 用語の定義と関連を明確にし、文書や会話で利用しつつ、プログラムに落としやすくする |
| 2 | 手法 | ユーザーストーリー・会話の中から主要な単語を拾い、関連を詳細化することでモデル化する |
次回は、動的なモデルの生成について説明したいと思います。。。
comments powered by Disqus